上述介紹完整個RAG的流程,各位有沒有想過我們怎麼產生知識庫?就是需要使用我們的向量資料庫,向量資料庫是一種專門設計用於存儲和檢索向量數據的資料庫系統。
等這些著名的向量資料庫!
那我們該怎麼把文字轉成向量呢?甚至是如何完成相似性搜索讓判斷最具有相關性?
大概可以分幾個點來理解,因為我們需要轉換為電腦能夠理解的語言,所以使用了向量的方式讓電腦理解我們的思維及想法,所以在做向量會需要很多工大概是以下:
電腦有了這些數據之後即可使用語義搜索 ,可以參考以下圖片:
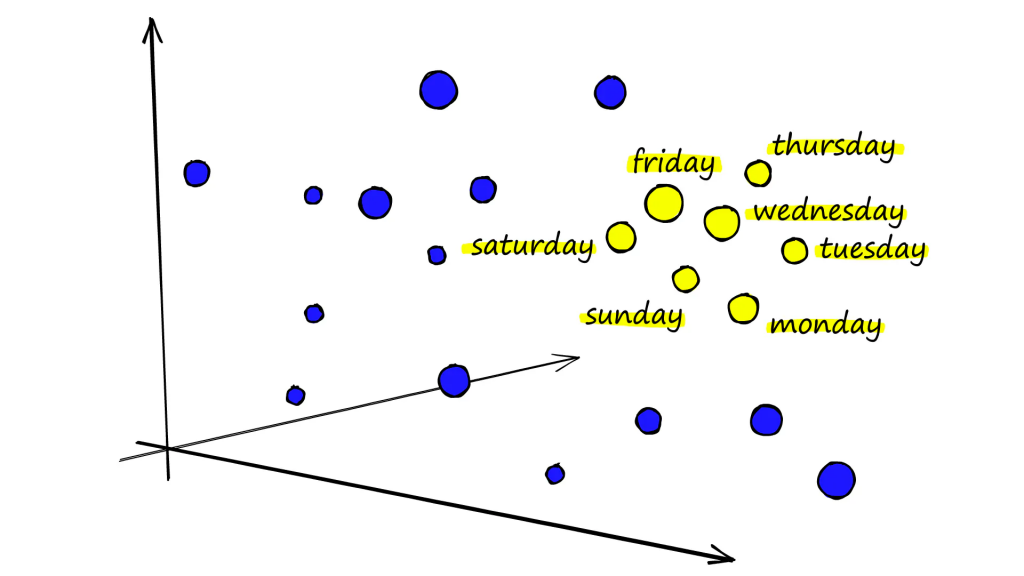
向量通常會有許多維度,語義越相近,向量數值就越近,所以相似度越高會讓我們的結果產生最相關的上下文。
完整的資料可以參考以下,可以更明白演算法的過程!
參考資料:https://www.pinecone.io/learn/series/nlp/dense-vector-embeddings-nlp/

